The task of decomposition or division of a character into elements is to represent a complex two-dimensional image in the form of a linear sequence of more simple images or elements, or graphs. I will give a strict definition of the graph later, but for now we will assume that all the Chinese characters consist of graphs. Each character consist of at least one graph, and there are no other elements in the hieroglyphics, except graphs. Therefore, each character can be uniquely described by the sequence of its graphs. Traditionally, all the systems of graphical decomposition of characters suggests doing it from left-top to right-down, and from outside into inside, and it is correct, as it is a natural way of image recognition, as we remember. And we are not going to break the tradition. Tradition is a good thing, and you may break it only when it is very necessary. You will tell me immediately that in this case I can not avoid collisions, for some characters consist of identical sequences of graphs, but having different relative position left-right or top-down. Experience shows that attempts to take into account the relative position of the elements would unnecessarily complicate the decision. Two characters: 员and 呗, - unfold in the same sequence of graphs: 口 and 贝. We can describe the first character as "口 above 贝", and second as "口 ahead 贝". But instead of adding two additional parameter for the mutual arrangement of their graphs for each character ("above" and "ahead"), we will add to sequence of graphs of one character one symbol, for example, "*" to indicate a some difference of one graphs sequence from another. Then, we will describe character 员 as sequence "口, 贝", and 呗 as sequence "口, 贝, *". Symbol "*" is "blank graph", it doesn’t exist in the character, it exists in a character description as a some "modifier graph". But otherwise it is a full-fledged graph.
It is clear that the set and amount of graphs used for characters decomposition depends on the number of analyzed characters. It's believed that there are more then 80 thousands Chinese characters. UNICODE describes about 25 thousands of characters. I have selected for analysis from all this diversity simplified characters only that used at least once per million characters of text in modern Chinese language (see: http://www.lancs.ac.uk/fass/projects/corpus/data/Chinese_character_frquency_list.zip). Those turned out to be slightly more than four thousand three hundred characters.
As a basis for a set of graphs for characters decomposition was used a classic set of Kangxi radicals. Some radicals were excluded from the list of graphs because of the rarity of their use, some of the symbols that were not radicals were added to the set of graphs. Also some variants of radicals were used as separate graphs. In particular, 扌 variant of 手 was used as separate graph, and 亻 variant of 人 was used as separate graph too. As a result, the whole set of graphs consist of 200 graphs now. Is it too much? Classic Kangxi set consist of 214 radicals. And it does not anger anyone.
We can say that the graph is not a "picture", not a part of the graphic representation of a character, but a formal unit for describing the composition of a character. So the graph 刀, for example, can "encode" in the description of the character such elements of a character as 刀, ⺈ and 刂. You know them as variants of classic Kangxi radicals. You can see all the graphs and their variants in the following table.
So, we have four thousand three hundred characters and two hundreds of his elements. After some effort we have the description of each these characters by a linear sequence of its graphs. Now we can tell to computer about all this things and make it do our work for us. For example, we can ask the computer: "Show me all characters containing graph '人'." And computer will show 274 different characters which include graph '人'. "And what about two graphs '人'?" Computer will show 29 characters which include 2 graphs '人': 从, 众, 坐, 纵, 丛, 耸, 巫, 怂, 挫 and so on. "And three graphs '人'?". We have only one such character in our set: '众'. We will call this selection algorithm free, because it select characters with any graph in any position. Let's complicate the task, let's ask computer to show all characters containing graph '人' in first position. 45 characters contains the graph '人' in the first position. And so we can choose characters with any sequence of graphs in any positions. It's most important, then we have full information about sequence of graphs for each character. This allows us to implement any conceivable algorithm to select characters. So we can choose characters with the same graphs in the same positions. And thus we can see all characters with similar block of graph, for example: 侯, 喉, 猴, 候 or 令, 领, 邻, 翎, 瓴, 冷, 怜, 铃, 拎 and so on. We remember, that similar images with small differences are easier to remember together. And we can see the similarities and differences now effortlessly. We will call this algorithm serial.
Since we have such an opportunity to freely "play" with the sequence of graphs, we can develop an algorithm for quickly searching for any predefined character. As a result of this "free game" with graph sequences, an fsl-algorithm appeared. "Fsl" means "first, second, last". This algorithm supposes, that user entered first, second and last graphs of character. It turned out that the overwhelming majority of the characters can be uniquely identified by this sequence: first, second and last. With a very rare exception. This is the fastest and simplest algorithm to search for unknown characters in dictionary, for example.
Let us make one more experiment. For example, we need a character 骤. This character consist of 9 graphs (马, 耳, 又, 丿, 丨, 丶, 丿, 丿, 丿). But as soon as we point two first graphs, our "game" tell us that only one character has this sequence of graphs in its composition. Congratulations, we have just found marker for the first character. Marker is some sequence of graphs that uniquely identifies a particular character. And we can found such markers for each character. I have done it for more then four thousands characters (using fsl-algorithm, of course). And it turned out than the marker is equal to or less than the total sequence of graphs of a particular character, but it is never more than three graphs. More over, it turned out than more than 70 % of characters has two graphs markers. And, if we take into account the frequency of usage this characters (thanks to dr. R. Xiao), we will get better result: only each fifth character in real text needs three graphs. And never more! It's great that the marker always starts with the first graph of the character. The second graphs of markers is the second or the last graph of total sequence of graphs of the character. The third graph of markers almost always is the last graph of character. And very rarely it can be third graphs of character, as You remember from the first part, for characters 暧 and 暖. It's a good illustration of natural way of image recognition: our view goes from the beginning to the end, and if that's not enough, goes "inside" image. Composition input is natural and fastest method writing of Chinese characters.
A good game for memorizing characters, isn't it?
How can we verify the correctness of remembering the character in this game? Surely, you need to enter it correctly in response to a request for its meaning (or pronunciation). Now we are going to do it.
We can realize these "abstract" ideas in the form of
specific applications that can make life easier for us in the
study of hieroglyphics. First of all, we can design
application for remembering characters. Because each character
consist of graphs, because we analyze it and remember it as
sequence of graphs, we can reproduce it as a sequence of
graphs. Therefore, we must provide to the user with entire set
of used graphs in the form of a convenient to choose matrix of
graphs. This is a separate task, and how we resolve it will
depend on the convenience and efficiency of our application.
200 graphs, it's quite a few. Let's arrange them in our
supposed matrix so that the most frequently used graphs are
concentrated in the center, and the ones met rarely closer to
the edges. For example, like this:

In this matrix, the following is interesting: graphs of 10 central columns occur in 90 percent of characters, and graphs of 10 peripheral columns in the remaining 10 percent of characters. I.e. we will use only this part of the matrix most of the time:

The remaining graphs we will arrange without changing their mutual position in such a matrix:

And we'll call it on the screen only by necessity with a separate button, just like we switch on uppercase letters on the keyboard. This will allow us to run the application on devices with a small screen. For example, I have tested it on tablet with 10 inch screen.
Well, now we can see, how it looks.
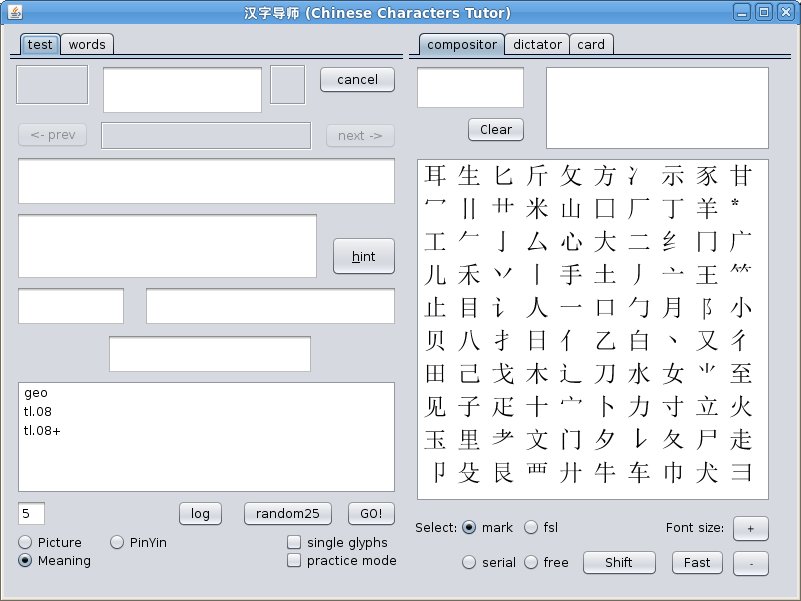
Two panels: left and right, - with two tabs
on left panel and three tabs on right panel, many windows,
buttons and check-boxes. Don't be afraid. It's not simple,
it's very simple. Test it and You will like it. Main tab is test,
but we start from words tab, because for testing we
need a prepared lesson.
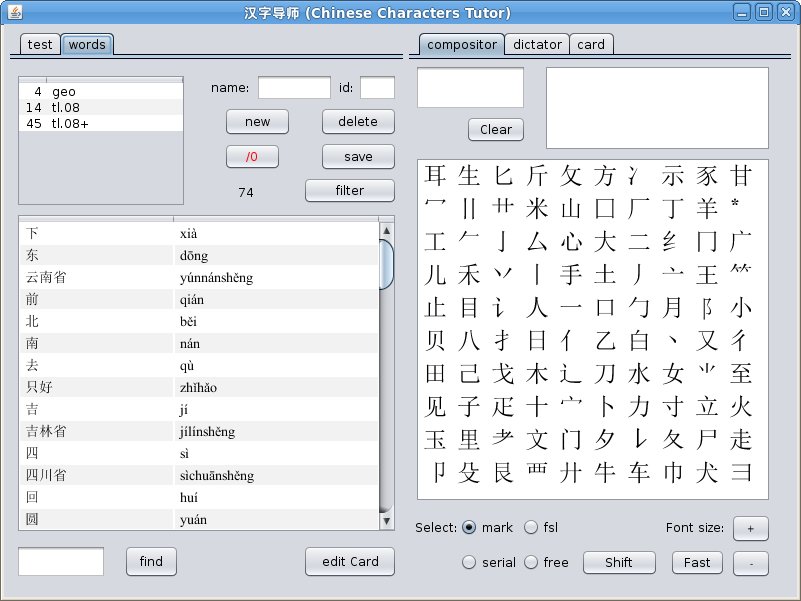
You see the list of the lessons at the top of the tab. You can control this list by group of buttons on the right of the list, You can add new lessons, edit or delete them. Below is a list of words known to the application. Filter button above the words list outputs words which belong to lessons pointed in lessons list. (You will need button "/0" later, it resets all results of the selected lessons to zero.) Little window on the bottom of the left panel helps You find character in the words list. Just put character (or word) into this window (Ctrl+V) and press find button. If the desired word is not in the dictionary, application suggest You to add it. A new window will be opened in which you will need to fill in all the blank fields and click the Save button.
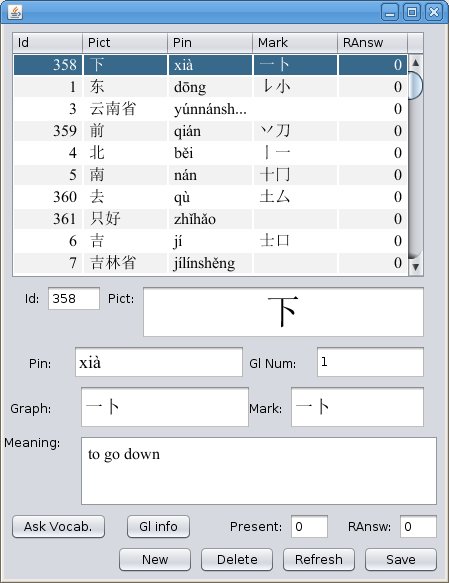
Useful buttons Ask Vocab. and Gl info
help You to obtain needed information. This window You can
also open by pressing edit Card button on previous
window.
If You click on any word in words list, card tab will be opened on right panel.
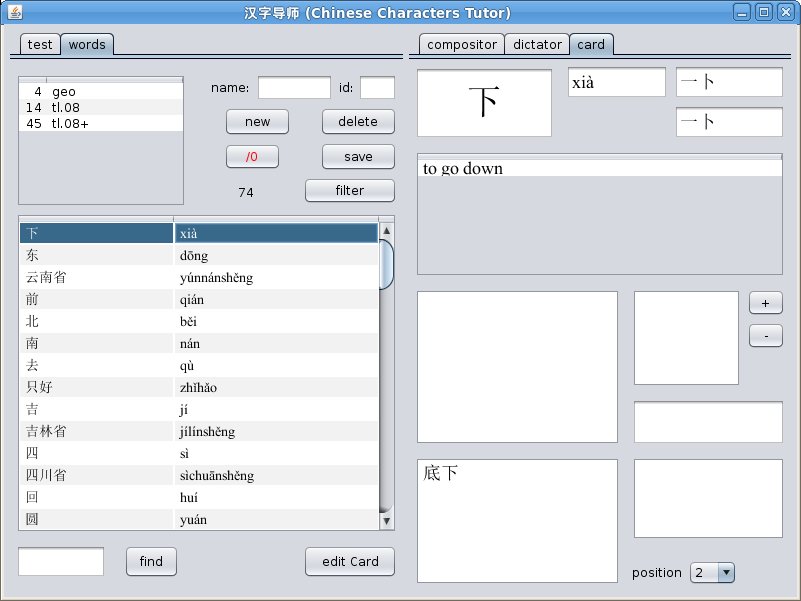
Everything is ultimately simple on this tab: You can see
a character (or word), its pronunciation (in pinyin), its
structural composition or full sequence of its graphs, its
marker, list of its meanings and list of lessons for each
meaning. You can add of delete lessons for current meaning by
+ and – buttons (don't forget to select the desired lesson in
lessons list to add it). For some characters additional
information may be shown: in which characters this one is a
component, and which characters are a components of this one.
Immediately You can see part of what words and in what
position this character stands.
The most interesting is compositor tab on the right panel. It's the main part of this application and all other apps based on composition input. We will "compose" characters on this tab. This is the same matrix of graphs, which we talked about at the beginning and two windows above it: graphs and characters window. The radio-buttons Select switches the above selection modes: free, serial, fsl and mark modes. You must enter desired sequence of graphs by mouse clicking (or finger touching, if You have touch screen), application shows it in graphs window. Depends on selection mode application returns a list of characters in characters window, and You must choose required character by mouse (or finger). The Fast button turns on the quick input mode when the single character from the characters window is automatically transferred to the test response window. You will need this later when You gain some skill and will work on increasing speed of response. I recommend You to play with selection modes, it will be useful experience. As You can see, graph matrix on compositor tab is represented by its first part. To switch matrix to second part You can use Shift button.
Now You may go to the main and simplest tab test.
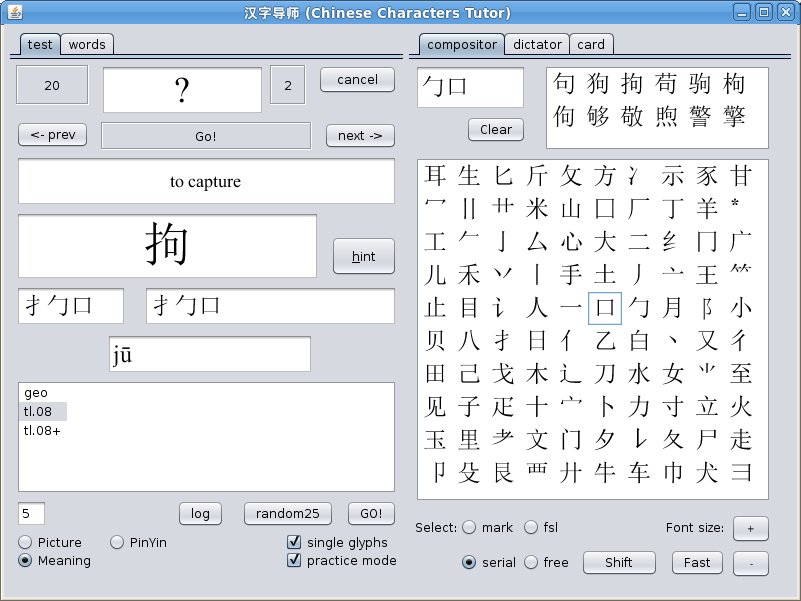
You must choose the desired lesson (or lessons if You want) and click Go! button. For the first time I recommend You to check single glyphs check-box and practice mode check-box. You can look through the entire lesson (use next → and ← prev buttons). When You decide to train enough, you can disable practice mode and start the test. Cancel button delete wrong input in the test response window. You can see log after finish testing (log button). After five sequential right answers character considers as known and will not presented for testing. This value is shown in a small window below lessons list and You may change it for current session. One wrong answer resets the amount of right answers to zero. Alas.
Please note, the picture shows input in serial
mode. It is interesting mode and we talked about it in the
first part. In characters window shown those
characters in which exact graphs sequence "勹口" is present and
You can see a characteristic block, presented in the
composition of each shown symbols.
And last thing: three radio-buttons on left-bottom. What will application ask You: meaning, pronunciation or picture only. The last mode useful if You know meaning and pronunciation of each characters, but You need practice in speed input of characters.
That's all. We did it.
Oh, I forgot about last tab – the dictator. It does not matter. It's almost standard tool for phonetic input. You can use it of course, but it's not interesting now. You can easily master it yourself.
You can download this
application and use it for your own pleasure and for the
benefit of mankind.
Now I have added another tool for those who
want to pass the HSK test but don't want to learn more words
than in this test. This is a simplified version of the
previous tool with a full actual list of HSK words by levels.
Thanks to Ma Chao (马超), Director of The Harbin
Mandarin School, who kindly provided an up-to-date
official list of HSK words. (By the way, if you want in
addition to learn to write well and quickly, you also want to
get a good practice in conversational Chinese in a favorable
language environment, I recommend that you turn to Ma Chao at
The Harbin Mandarin school. In addition to good Chinese, you
will get a flexible schedule, flexible program, inexpensive
accommodation in three minutes walk from the school in a
beautiful city. I've been in contact with Mr. Ma for almost
two months, both at school and outside, and I can testify that
besides Mr. Ma being an intelligent teacher, he's also just a
good guy. Come, you will not be bored. :)
There are more tools for fast writing and for easily remembering graph matrix. You can download and master them yourself too. It's very simple and there is no need to explain anything.
And, surely, You can see now how does it look in two variants: slowly and thoroughly and quickly as far as I can.
Good Luck.
Please feel free to contact me if you need: support@poutko.ru.
Sincerely Yours
B. Poutko.
The End.
Sorry, no, not the end. Now You can test on-line version
of similar tools: reduced
Writer and simple Chinese-English dictionary with
Compositional Input method only, without phonetic input. Short
description lies here.
Now the end.
...while :)..
There are two other
interesting utilities: Virtual Keyboard for PC (You can
obtain it here) and the same for
Android. For Android version, please, go to ChinaTouch Typing Inc.
The Real End (...may be...)